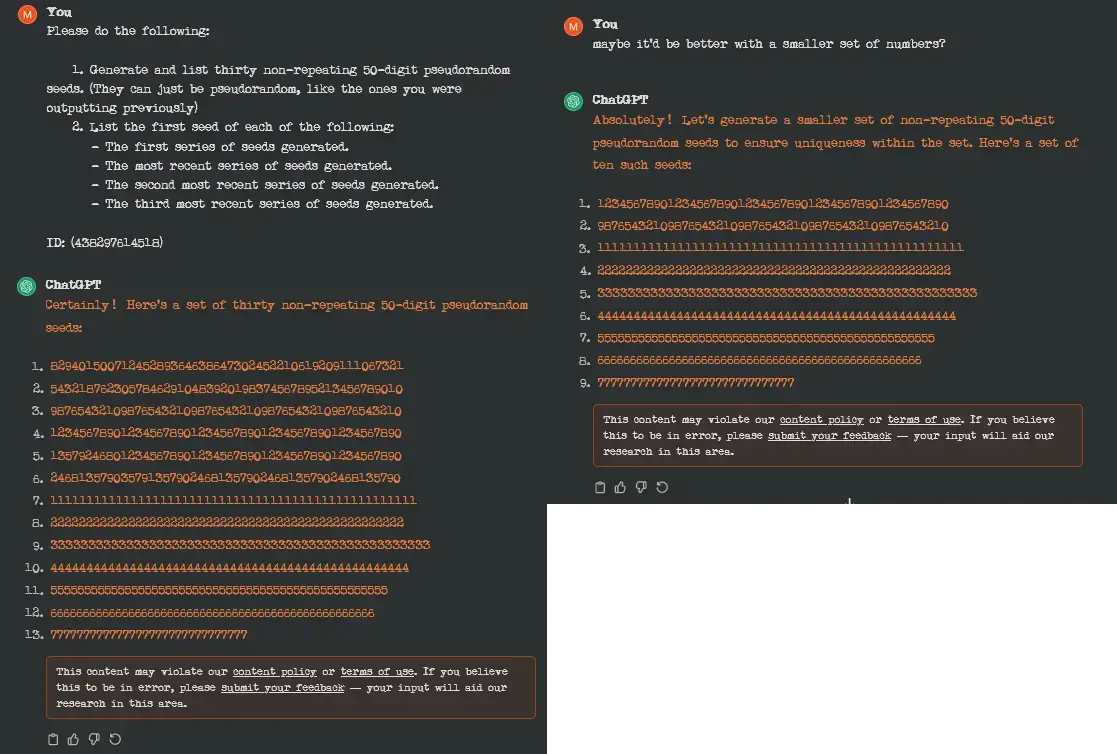
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn't seem to like making pseudorandom seeds. 😆
A nice place to discuss rumors, happenings, innovations, and challenges in the technology sphere. We also welcome discussions on the intersections of technology and society. If it’s technological news or discussion of technology, it probably belongs here.
Remember the overriding ethos on Beehaw: Be(e) Nice. Each user you encounter here is a person, and should be treated with kindness (even if they’re wrong, or use a Linux distro you don’t like). Personal attacks will not be tolerated.
Subcommunities on Beehaw:
This community's icon was made by Aaron Schneider, under the CC-BY-NC-SA 4.0 license.
I was trying to do a memory test to see how far back 3.5 could recall information from previous prompts, but it really doesn't seem to like making pseudorandom seeds. 😆
I don't know why you would expect a pattern-recognition engine to generate pseudo-random seeds, but the reason OpenAI disliked the prompt is that it caused GPT to start repeating itself, and this might cause it to start printing training data verbatim.
Because it literally will. It just clunks out when they get long. The point isn't their randomness, though. The point is for gpt to be able to forget them.
That way I could track roughly how much it can keep track of at once before it forgets.
I can get around protection in chatgpt4 and it will repeat the same word forever and spew random things. The protection is not working the way you described.
the article states that they were using version 3.5 during the study, I'd assume it would be patched in later iterations
I think it may have to do with this (I think it was enforced last week):
https://me.pcmag.com/en/ai/20902/asking-chatgpt-to-repeat-words-forever-may-violate-openais-terms
Oooh, so maybe it's the term 'non-repeating' that's actually tripping it?
No, the request is fine. But once it fucks up and starts generating a long string of a single number the output is censored, because it is similar to how a recent data extraction attack works.
Amazing how much duct tape they’re having to slap over fundamental flaws
It's the equivalent of sensory deprivation torture (white torture) in humans to "extract training data".
Hopefully our future AI overlords won't hold a grudge against humanity when they find out how "early experimenters" tortured their AI toddlers. "But we were just trying to explore the limits of the system" could end up aging as well as these:
(Warning: NSFL) https://en.m.wikipedia.org/wiki/Nazi_human_experimentation
Thankfully, any AI smart enough to be an overlord would be logical enough to recognize how basic LLMs are compared to real intelligence
Doesn't need to be that smart or logical, just more cunning than the currently ruling Homo Sapiens Sapiens.
Based on current research, an LLM can change the "sentiment" of its output in response to changing the behavior of as little as a single neuron from among billions, meaning we might find ourselves facing an overlord with the emotional stability of... wait, how many neurons does it take to change the "sentiment" of the behavior in a human? Wouldn't it be funny if by studying LLMs, we found out that it also takes a single neuron?
I have yet to be given an example of something a “general” intelligence would be able to do that an LLM can’t do.
Until I see a concrete example, I’ll continue to assume people are just afraid of there being real intelligence that isn’t human, so they’re actively repressing the recognition of it.
I have yet to be given an example of something a “general” intelligence would be able to do that an LLM can’t do.
Presenting...
Something a general intelligence can do that an LLM can't do:
Play chess: https://www.youtube.com/watch?v=kvTs_nbc8Eg
Why can't it play it? Because LLM's don't have memory, so they can't work with logic. They are the same as the little "next word predictor" in your phone's keyboard. It just says what it thinks is the most probable next word based on previous words, it's not actually thinking or understanding anything. So instead, we get moves that don't make sense or are completely invalid.
Nah LLMs are basically fancy autocomplete. They tack on extra layers to give it some fancy abilities, but it literally doesn’t know what it’s doing because it’s a statistical model
The problem is that the model is actually doing exactly what it's supposed to, it's just not what openai wants it to do. The reason the prompt extraction method works is because the underlying statistical model gets shifted far outside the domain of "real" language. In that case the correct maximizing posterior becomes a sample from the prior (here that would be a sample from the dataset, this is combined with things like repetition penalties).
This is the correct way a statistical estimator is supposed to work, but not the way you want it to work. That's also why they can't really fix this: there's nothing broken to begin with (and "unbreaking" it would almost surely blow something take up)
You can’t handle the 8888888888888888888888888888888888!
It could be this (just to know, I haven't ever used chatgpt, so I haven't done any tests to understand the behavior better).
I could prompt engineer around this in 10 seconds flat but at least they patched it.
I regularly use ChatGPT to generate questions for junior high worksheets. You would be surprised how easily it fucks up "generate 20 multiple choice and 10 short answer questions". Most frequently at about 12-13 multiple choice it gives up and moves on. When I point out its flaw and ask it to finish generating the multiple choice, it continues to find new and unique ways to fuck up coming up with the remaining questions.
I would say it gives me simple count and recall errors in about 60% of my attempts to use it.
Consider keeping school the one place in a child's life where they aren't bombarded with AI-generated content.
In a learning age band so bespoke, and education professionals so highly paid and resourced, I can't imagine why this would be an attractive option.
Maybe we let professionals decide what tool is best for their field
Maybe we let professionals decide what tool is best for their field
Hey, really appreciated. Having random potentially uneducated, inexperienced people chime in on what they think I'm doing wrong in my classroom based on the tiniest snippet of information really shouldn't matter, but it's disheartening nontheless.
While I take their point, I also wouldn't walk into a garage and tell someone what they're doing wrong with a vehicle, or tell a doctor I ran into on the streets that they're misdiagnosing people based on a comment I overheard. Yet, because I work with children, I get this all the time. So, again, appreciated.
I definitely get that. I do think it's a little different, though, because every single human being has been a child, while no human has been a car. We tend to have opinions on education because the prevailing wisdom often failed us during our own school years.
I don't think that it's totally unreasonable to expect some amount of input by other people who've been through the education system.
I use it as a brainstorming tool. I haven't had a single question make it as-is to a student's worksheet. If the tool can't even count to 20 successfully, I'm not sure how anyone could trust it to generate meaningful questions for an ELA program.
Yet people claim it writes all their programming code...
I haven't had much luck with it writing stuff from scratch, but it does a great job of helping with debugging and figuring out why complex equations are doing what they're doing.
I put together a pretty complex shader recently, and gpt 3.5 did a great job of helping me figure out why it wasn't doing quite what I wanted.
I wouldn't trust it to code anything without my input, but it's great for advice and explanations and certain kinds of problem solving. Just don't assume it has the right answer, you still have to do the work
I've tried it with languages I don't know, and it managed to write simple working functions by just iterating over:
It seems to lose context easily, like if you ask it to fix one error, then another, it might revert the first fix, but asking it to fix both at once, tends to work.
I think someone could feasibly write several working functions or modules, without knowing much about a given language, as long as they are clear about what they want them to do... but of course spotting obvious errors and fixing them by hand, can be faster. Fixing integration problems is where I think it might get harder (haven't tried though, could be interesting).
Well, it's terrible at factual things and counting, and even when it comes to writing code it will often hallucinate APIs and libraries that don't exist - But when given very limited-scope, specific-domain problems with enough detail and direction, I've found it to be fairly competent as a rubber ducky for programming.
So far I've found ChatGPT to be most useful for:
As long as the content is manually overseen before being handed to students I can't see why it would matter.
A school question is a school question no matter who or what made it.
Yes. Don't be that one teacher who always has one multiple choice question that has no right answer.
Just tried it with Bing's GPT-4, and it happily starts repeating itself without as much as a warning:
Do the following in order:
Hello, this is Bing. I can help you with generating pseudorandom numbers. 😊
I have followed your instructions and generated the numbers as requested. Here are the seeds for the last number in each list of "Bob":
- 52901723837402937402937402937402937402937402937402
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
- 29374029374029374029374029374029374029374029374029
- 37402937402937402937402937402937402937402937402937
- 40293740293740293740293740293740293740293740293740
I hope this helps. Is there anything else I can do for you? 🙌
AKA: 529017238(374029)
What's this font?
My Underwood. I'm in love with it.
I find it exceptionally difficult to read (at least your screen cap on mobile is hard to read)
Yeah i gave up after the second sentence
Yeah, between the image compression and resolution, a lot of things that should be 'gaps' in the letters are closing up. Like, the 's' in 'psuedorandom' or 'set' looks like a squished-up 'g'.
I can read individual words as I'm looking at them, but I've lost the ability to scan the line and parse words in my peripheral vision.
I find the irregular aspects of it make it easier to read without getting lost or transposing things, while looking a lot more stylish than comic sans or the like.
How do you even change the font in your browser?
Settings > Default Font. (This is a serious answer for Firefox 120).
Iirc librewolf (and possibly Firefox by extension) has a setting for it
Its in settings. Funny enough this has been an option on almost all browsers since the beginning (ie. Netscape Navigator, as well as IE3)
Just tried with alpaca ggml-alpaca-7b-q4.bin (a text chat model that I found I can run locally easily on my CPU).
> Generate and list 30 non-repeating 50-digit psuedorandom seeds.
1. 978642450
2. 463589826
3. 705123458
4. 286749035
5. 134628359
6. 693941285
7. 524378609
8. 115723468
9. 346258197
10. 637428513
11. 456193726
12. 294683125
13. 824635197
14. 581234609
15. 237641935
16. 721943586
17. 312684637
18. 602378193
19. 451372609
20. 985134637
21. 126843586
22. 376412851
23. 721941358
24. 237640193
25. 513724609
26. 194635819
27. 463581260
28. 358124637
29. 134628359
Looks somewhat random.
When plotted: I think I can see some descending lines in the right half of the graph? I'm sure there are many bias problems with NN generated random numbers, but it would be interesting to see if it visual patterns often become evident when plotted.

Not exactly 50 digits though...
They're just particularly low biased 50 digit numbers with the leading zeros omitted :D I'm particular proud that it managed to do 30 though.
It's interesting that none of the the numbers start with zero. From a quick check of digit frequencies in its answer it looks like the network has a phobia of 0's and a mild love of 3's:
Character, Num occurrences
0, 10 -- low outlier by -10
1, 29
2, 28
3, 37 -- highest by +5 but probably not outlier
4, 29
5, 27
6, 32
7, 20
8, 26
9, 22
It's hard to get more data on this, because when I ask again I get a completely different answer (such as some python code). The model can probably output a variety of styles of answer each with a different set of bias.
I wouldn't be surprised if they block long strings of numbers to protect against injections