We did it not because it was easy, but because we thought it would be easy.
NAT sort of accidentally includes what is called a "stateful firewall". It blocks inbound connections because it doesn't know where they should go. IPv6 eliminates the need for NAT but doesn't prevent stateful firewalls. It is just as easy to implement stateful firewalls (actually a bit easier) for IPv6 without NAT. The difference is that the choice is yours, rather than being a technical limitation.
For example if I had a smart microwave I would want to ensure that there is some sort of firewall (or more likely for me not connect it to the internet at all, but I digress). However I may want my gaming computer to be directly accessible so that my friends can connect to my game without going through some third-party relay, or maybe my voice chat can be direct between me and my friends for extra privacy and better latency.
Also relying on network-level protection like this is a good idea in general. Eventually a friend is going to come over with an infected network and connect to your WiFi. With just NAT this will allow the malware on their computer to access your microwave as they are "inside the NAT". If you were applying a proper stateful firewall you would likely apply it to all traffic, not just internet traffic.
Mostly dropping the analogy as it falls apart quickly once you try to talk about more specific details.
How do I handle whether I want my phone number to be known to the world?
If you don't want people to be able to call you then you can block incoming calls. This is sort of the like IPv4 NAT case, people can't connect in (unless you forward ports). Or if you want to you can allow incoming calls. The choice is up to you now rather than being forced by a technical limitation.
Does my phone number ever change on its own or can I freely change it?
Generally you will be provided a "prefix" by your ISP. In v4 this would typically be a full address. In v6 there are a huge number of addresses inside this prefix. In both cases how often the prefix chances is up to your ISP, but for v6 you can chance the suffix you use inside of the prefix as often as you want.
Who has the phone book?
There are two main parts of "the phone book". There is "Who owns this address?" and "How do I get to this address?" Both of these are basically identical between IPv4 and IPv6.
For "Who owns this address?" there is a global directory of assignments. This is typically done in multiple layers.
- The whole address space is split among reserved addresses and continental registries.
- The continental registries distribute addresses to organizations or individuals.
- The organizations and individuals distribute addresses to customers/devices.
- This may continue, for example if your home internet connection is assigned multiple addresses (rare on v4, expected on v6) then you can assign addresses to devices in your house.
For "Who do I get to this address?" A protocol called BGP is used to advertise where an address is available from. So I may say "If you want to get to addresses 32 to 64 come talk to me". This is sort of like in a hotel how there are signs saying which room numbers are in which direction. When two networks are connected they share this information between them to establish a "routing table", so they know how to get to everywhere else on the internet.
This may look something like this:
- Your laptop wants to talk to address 17. It has learned that addresses 1-8 are "local", everything else goes out your home internet connection.
- Your residential ISP is connected to 4 different other networks (likely a Tier 1 ISP), two of these have access to address 17, but one is "closer" so your ISP sends it there.
- This tier 1 ISP knows that a network it is connected to serves addresses 16-32. (Maybe this is your friend's residential ISP.) So it sends the traffic there.
- Your friends residential ISP knows that addresses 16-20 are assigned to your friends house, so it sends the traffic there.
- Your friends router knows that address 17 is their desktop, so it sends the traffic there.
Overall no single places knows how to get to every other address. But they know the best next step. So you don't know where 17 is, but you know to send it to your ISP, your ISP doesn't know where 17 is but knows that their partner tier 1 ISP knows how to get there, the tier 1 ISP doesn't know where 17 is, but knows that it belongs to your friend's ISP, your friends ISP doesn't know what device 17 is, but knows that it is in your friends house, then finally your friends home router actually knows that 17 is your friends desktop.
You can sort of imagine this like delivering mail. If I send mail in Canada that is addressed to England, Canada Post doesn't really care where exactly I am sending the letter. It just knows that it needs to forward it to Royal Mail and they will handle it from there.
I switched to Immich recently and am very happy.
- Immich's face detection is much better, very rarely fails. Especially for non-white faces. But even for white faces PhotoPrisim regularly needed me reviewing the unmatched faces. I also needed to really turn up the "what is a face" threshold because otherwise it would miss a ton of clear faces. (Then it only missed some, but also has tons of false positives). On the other hand Immich just works.
- Immich's UI is much nicer overall. Lots of small affordances. For example the menu item to "view in timeline" is worth switching alone. Also good riddance to PhotoPrism's persistent and buggy selection. Someone must have worked really hard on implementing this but it was really just a bad idea.
- Immich has an app with uploading, and it allows you to view local and uploaded photos in one interface which is a huge UX win. I couldn't find a good Android app for uploading to photoprism. You could set up import delays and stuff but you would still regularly get partially uploaded files imported and have to clean it up manually.
- Immich's search by content is much better. For example searching for "cat with red and yellow ball" was useless on PhotoPrism, but I found tons of the results I was looking for on Immich.
The bad:
- There is currently a terrible jank in the Immich app which makes videos unusable and everything painful. Apparently this is due to some Album sync process running in the main thread. They are working on it. I can't fathom how a few hundred albums causes this much lag but 🤷 There is also even worse lag on the location view page, but at least that is just one page.
- The Immich app has a lot less features than the website. But the website works very well on mobile so even just using the website (and the app for uploading) is better than PhotoPrism here. The fundamentals are good but it just needs more work.
- I liked PhotoPrism's advanced filters. They were very limited but at least they were there.
- Not being able to sort search results by date is a huge usability issue. I often know roughly when the photo I want to find was taken and being able to order by date would be hugely helpful.
- You have to eagerly transcode all videos. There is no way to clean up old transcodes and re-transcode on the fly. To be fair the PhotoPrism story also wasn't great because you had to wait for the full video to be transcoded before starting, leading to a huge delay for videos more than a few seconds, but at least I could save a few hundred gigs of disk space.
Honestly a lot of stuff in PhotoPrism feels like one developer has a weird workflow and they optimized it for that. Most of them are counter to what I actually want to do (like automatic title and description generation, or the review stuff, or auto quality rating). Immich is very clearly inspired by Google Photos and takes a lot of things directly from it, but that matches my use case way better. (I was pretty happy with Google Photos until they started refusing to give access to the originals.)
Most Intel GPUs are great at transcoding. Reliable, widely supported and quite a bit of transcoding power for very little electrical power.
I think the main thing I would check is what formats are supported. If the other GPU can support newer formats like AV1 it may be worth it (if you want to store your videos in these more efficient formats or you have clients who can consume these formats and will appreciate the reduced bandwidth).
But overall I would say if you aren't having any problems no need to bother. The onboard graphics are simple and efficient.
Yes. As this is a workstation the memory use is highly variable, >95% of the time I would probably barely notice having 32GiB. But other times it is a huge performance win to have that capacity available. Sometimes I am compiling lots of stuff and 32 compilers running + ample disk cache is very important. Other times I am processing lots of data and other times I am running a few VMs.
It is a bit of a luxury. I think if I was on a tighter budget I would have gone for 64GiB. However the price difference wasn't that much and at least a handful of times I have been quite happy to have that capacity available. And worst case I just have everything sitting in disk cache after a warm up which is a small performance win on every small task.
I have enough disk space.
Plus my /tmp is a ramdisk and sometimes I compile large things in there (Firefox) so it is nice to let it be flushed out to disk if there are more important uses for that RAM than holding a file that most likely won't be read again.
is framework agnostic
But it isn't, because they depend on framer-motion and React. JSX is, but the icons aren't.
You can trivially provide on-hover animations using CSS in SVG then your icons are framework agnostic. Not to mention smaller to download and more efficient to execute.
There are three parts to the whole push system.
- A push protocol. You get a URL and post a message to it. That message is E2EE and gets delivered to the application.
- A way to acquire that URL.
- A way to respond to those notifications.
My point is that 1 is the core and already available across devices including over Google's push notification system and making custom push servers is very easy. It would make sense to keep that interface, but provide alternatives to 2 and 3. This way browsers can use the JS API for 2 and 3, but other apps can use a different API. The push server and the app server can remain identical across browsers, apps and anything else. This provides compatibility with the currently reigning system, the ability to provide tiny shims for people who don't want to self host and still maintains the option to fully self host as desired.
% free -h
total used free shared buff/cache available
Mem: 125Gi 15Gi 90Gi 523Mi 22Gi 110Gi
Swap: 63Gi 0B 63Gi
I'll use it eventually. Just gotta let the disk cache warm up.
I don’t want the end executable to have to bundle these files and re-parse them each time it gets run.
No matter how you persist data you will need to re-parse it. The question is really just if the new format is more efficient to read than the old format. Some formats such as FlatBuffers and Cap'n Proto are designed to have very efficient loading processes.
(Well technically you could persist the process image to disk, but this tends to be much larger than serialized data would be and has issues such as defeating ASLR. This is very rarely done.)
Lots of people are talking about Pickle. But it isn't particularly fast. That being side with Python you can't expect much to start with.

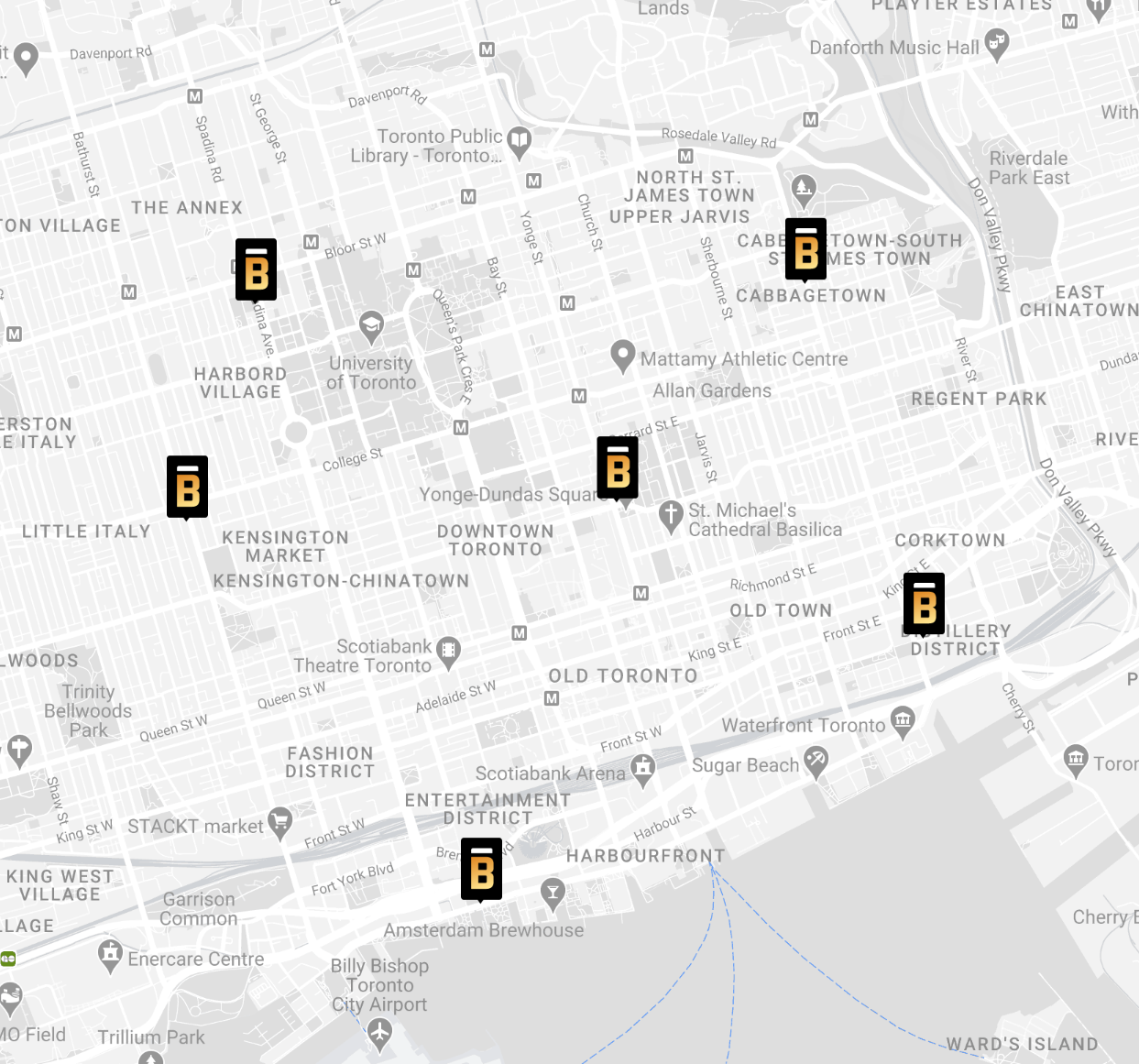
This is frustrating. I live in a small apartment and my nearest beer store is over 20min walk. I can get to at least 6 LCBOs in that time and dozens of grocery stores that sell alcohol. I'm not even the worst off..
Note that in the map posted the middle location is Yonge and Dundas which doesn't accept bottles. So if you live in the downtown core you can be walking 30min easy (each way).
You can see a map here, but which ones accept bottles or not aren't indicated until you click "show details". https://www.thebeerstore.ca/locations
How is this acceptable? I am forced to pay a deposit on every bottle but have nowhere to return them. Either I save up and haul a giant bag 20min or drive. Either way a waste of space in my apartment and I don't even drink that much.
It seems that we need a solution.
- Make LCBOs take bottles back. (or anywhere that sells alcohol, including Beer Store delivery)
- Remove the deposit and recommend recycling (sucks for bottles which are better washed and reused rather than crushed and reformed).
- At least make the Yonge and Dundas store accept empties. This would at least give options in downtown core that are less than 15min away. Still not great but closes a gaping hole.
view more: next ›
It honestly sounds more like someone convincing you that crypto is great than someone convincing you that Greenpeace is great.