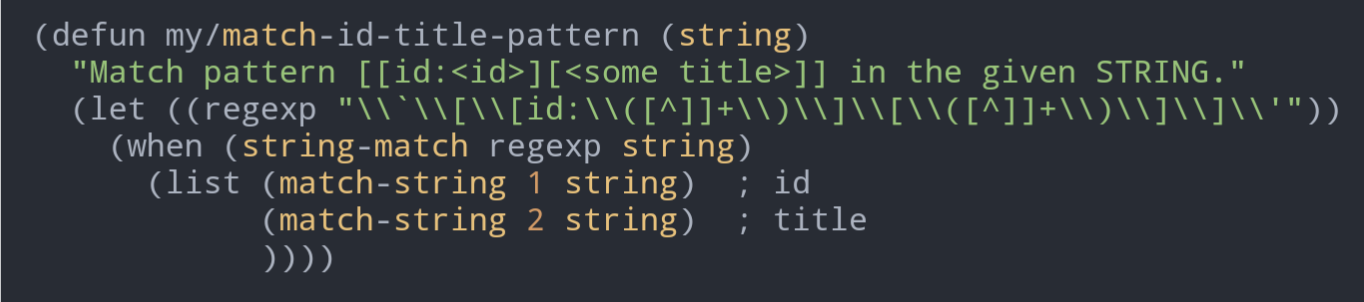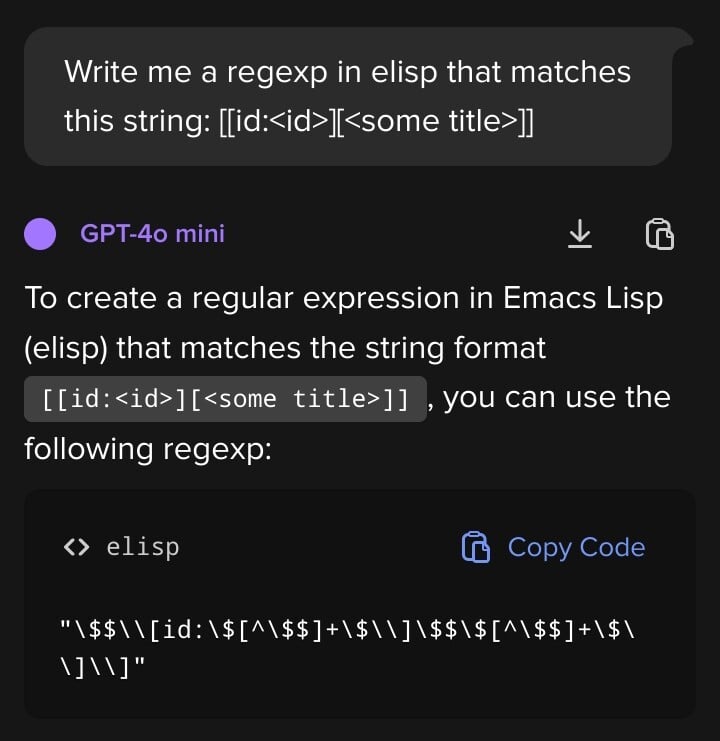
Management: Fuck it, ship it.
The people at the top honestly don't give a fuck if it barely works as long as it's an excuse to cut costs. In things like Customer Service, barely working is a bonus, because it makes customers give up before they try to get their issue solved.