Hello! Let me first clarify, this is for a personal project, based on an idea I always use to learn all kinds of things: personal finance tracking.
The DB model I typically use looks something like this:
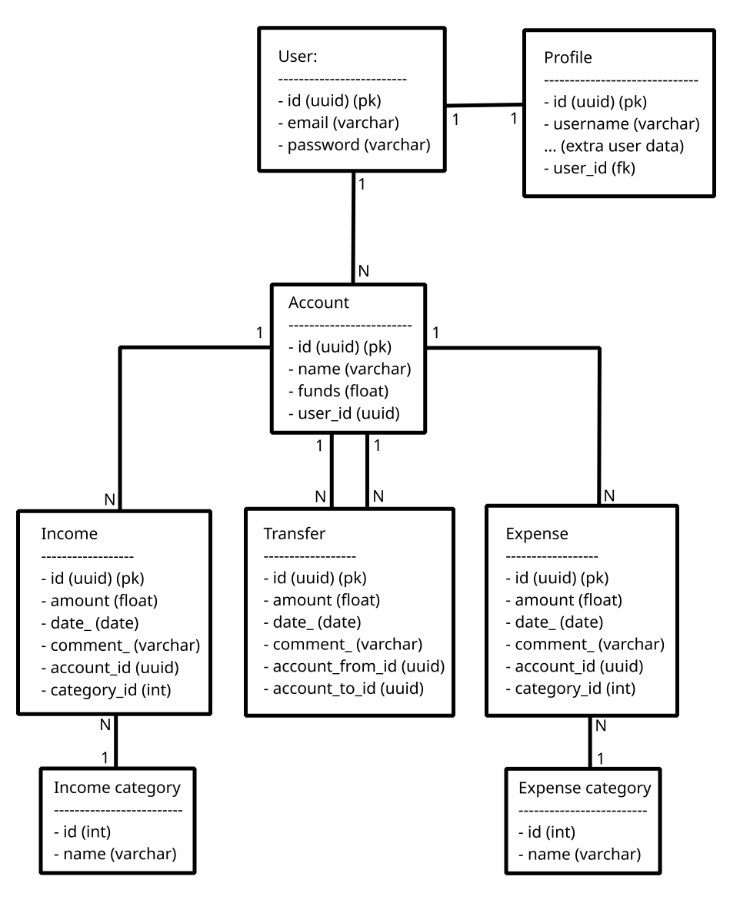
Initially, I made the decision to separate incomes, expenses and transfers into separate tables, which makes sense to me, according to the way I learned DB normalization.
But I was wondering if there is any benefit in somehow mixing the expense and income tables (since they are almost identical, and any code around these is always almost identical), or even all 3 (expense, income and transfer). Maybe it is more convenient to have the data modeled like this this for an API, but for BI or analytics, a different format would be more convenient? How would such format look like? Or maybe this would be better for BI and analytics, but for an API it's more convenient to have something different?
A while ago at a previous job, an experienced software architect once suggested, for a transactional system, to separate the transactional DB from a historical DB, and continuously migrate the data differences through ETL's. I have always thought that idea is pretty interesting, so I wonder if it makes sense to try in my little personal project.
If it was you, how would you model personal finance tracking? Is there something you think I may be missing, or that I should look into for DB modeling?
(Note: I intentionally do not track loans / investments, or at least I have not tried to integrate it for the sake of simplicity, and I have no interest in trying YET.)
In my mind, tables being identical is indeed a code smell. Combine them and add a type column, if you're going for normalization.
The one exception, for me, would be if there's a performance issue. For example, I frequently work with data where we want to maintain history, and the easiest way to do that is to dupe each record, every time it changes. A "normalized" solution would have you do that in the same table, and just add a version ID to each record. But with a high volume of data (that you're probably going to use VERY sparingly) that may either cause reduced performance, or just be annoying to deal with (I.E. constantly having to remember to filter to just the most-recent versions).
Also, from a higher-level business perspective, look into ledger-based accounting. It's the generally-used system among professional accountants and accounting software. One transactions (or distributions) table (I.E. the ledger) contains all movement of money, in the form of dollar amounts being moved from a source account to a destination account. Accounts are categorized as Expenses, Income, Assets, or Liabilities (also sometimes Equity). So, if you pay an electric bill, that's just a transaction/distribution moving money from an Asset account (E.G. "Checking XXXX") to an expense account (E.G. "Utilities: Electricity"). Tracking expenses and income becomes simply a matter of looking at account balances, and auditing is performed by making sure all account balances, when they're tracked ot built maybe from separate systems, or separate ledgers, add up to $0.
I agree I should get a grasp on ledger based accounting before my next project. Thanks for pointing me in the right direction!