LongChat, with alternative versions available on GPTQ and GGML, stands out as one of the first newer models that has been specifically fine-tuned for 16K context length using the RoPE scaling technique. This innovative method was developed by kaiokendev.
Along with this groundbreaking model, they also launched LongEval, an evaluation framework created to assess the ability of models to effectively utilize their extended context.
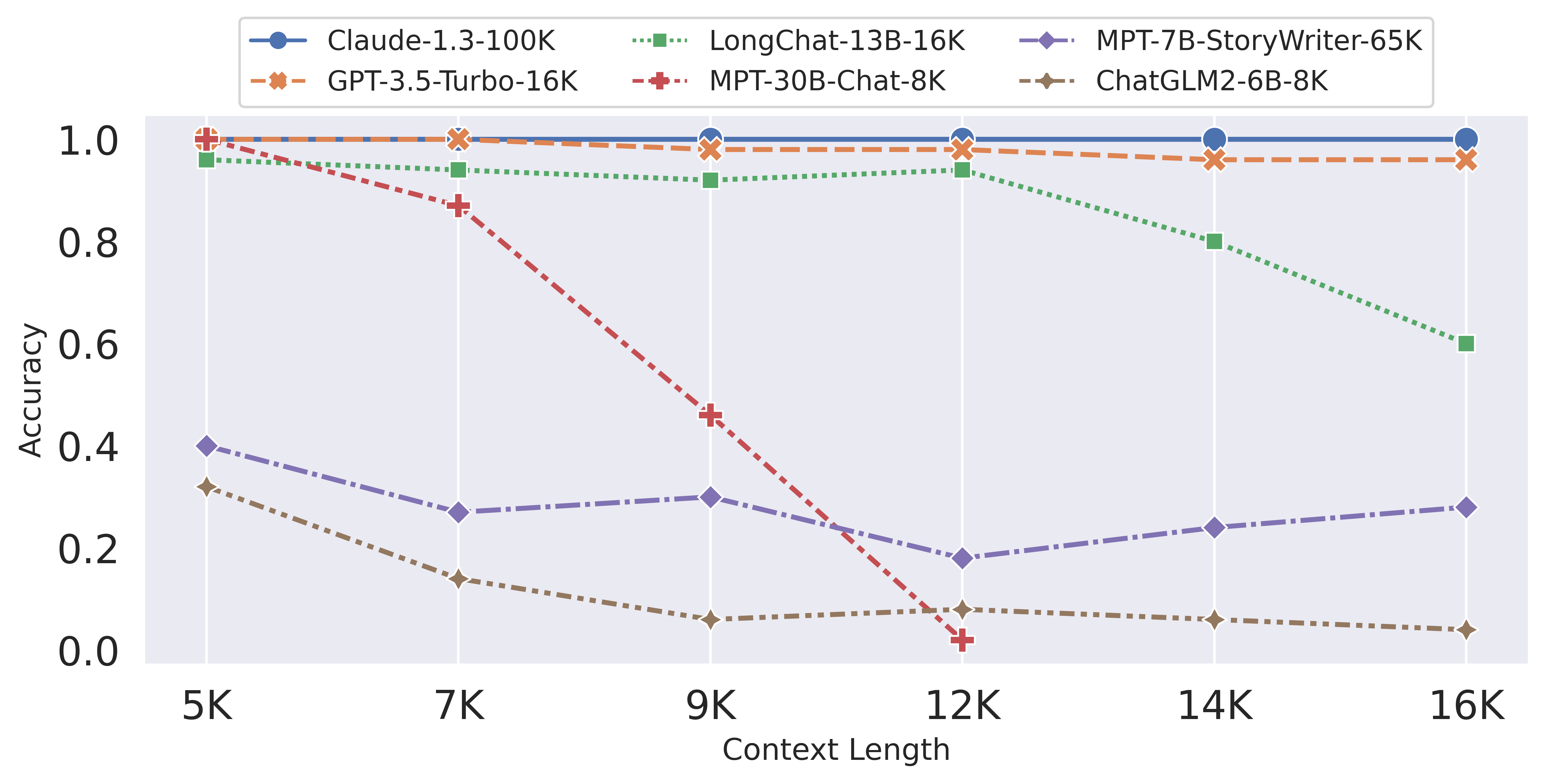
Beyond testing their own model, the team also conducts evaluations on most other models claiming high context capabilities.
Human preference benchmark (MT-bench)
In the previous section, we observed that LongChat models perform well on long-range retrieval tasks, but does this come with a significant drop in human preference? To test whether it still follows human preferences, we use GPT-4 graded MT-bench, a set of challenging multi-turn conversation questions.
Table 2. MT-bench scores comparing LongChat-13B to other models of similar sizes.
| Model | MT-bench (score) |
|---|---|
| LongChat-13B-16K | 5.95 |
| Vicuna-13B | 6.39 |
| WizardLM-13B | 6.35 |
| Baize-v2-13B | 5.75 |
| Nous-Hermes-13B | 5.51 |
| Alpaca-13B | 4.53 |
We find that LongChat-13B-16K is comparable to its closest alternative - Vicuna-13B, which indicates that this long-range ability does not come with a significant sacrifice of its short-range ability. At the same time, LongChat-13B-16K is competitive compared to other models of the same size.
To support the LMYS project, you should visit their site here and catch the full article in detail
If you found any of this interesting, please consider subscribing to [!fosai@lemmy.world](https://lemmy.world/c/fosai) where I do my best to keep you in the know with the latest advancements in artificial intelligence.
I have many more posts and projects in the works that I am very excited to share with you soon. For now, I hope you enjoy these updates as I present to you information when it is available to me.