A short journey to long-context models.
Why does it matter?
Training models beyond the 8k context have the following problems:
- the perplexity deteriorates as context length increases
- inability to train with longer context, while keeping the VRAM requirements
- retraining is needed to increase the context size
Attempt to solve this
Tom's code compatible to transformers library
Loss of Fluency
All LLMs that have been trained so far suffer from a loss of fluency as the input grows too long. When this occurs, the model will lose the ability to produce language, and starts generating e.g. endless newlines, arbitrary characters.

Local LLM runs out of VRAM on subsequent prompts.
Fluency patched
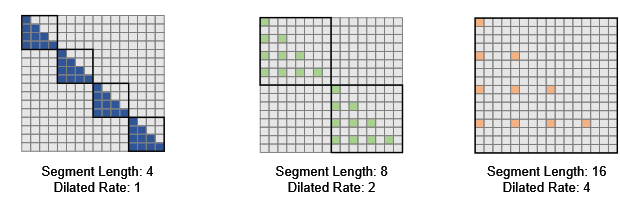
a) LongLoRA has a 2-step process.
Shift short attention:
def shift(qkv, bsz, q_len, group_size, num_heads, head_dim):
qkv[:, num_heads // 2:] = qkv[:, num_heads // 2:].roll(-group_size // 2, dims=2)
qkv = qkv.transpose(1, 2).reshape(bsz * (q_len // group_size), group_size, num_heads, head_dim).transpose(1, 2)
return qkv
Unpacking after attention computations:
output[:, :, self.num_heads//2:] = output[:, :, self.num_heads//2:].roll(group_size//2, dims=1)
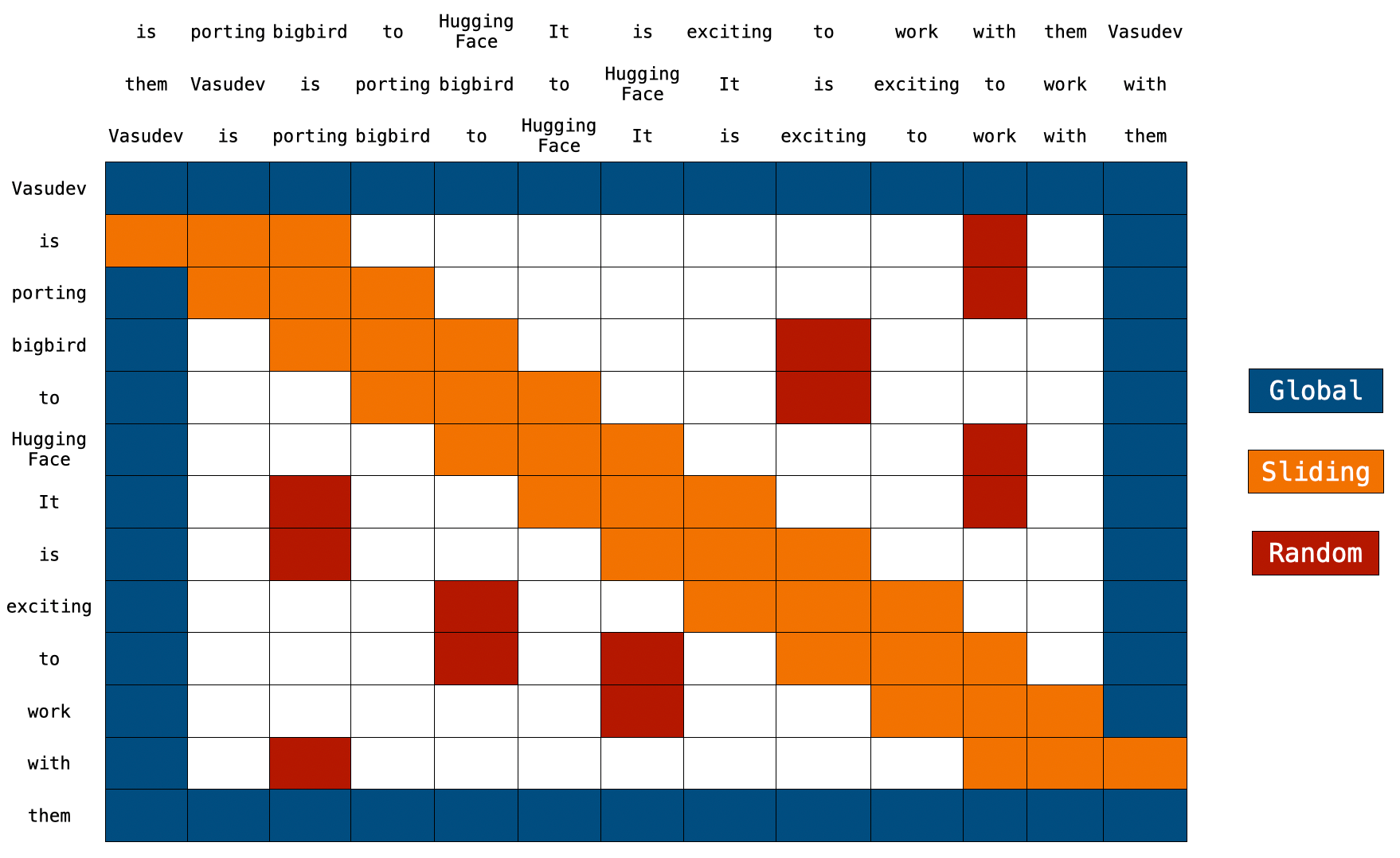
b) Tom's compatibility layer wraps StreamingLLM implementation, it implements an interface similar to the transformers library.


from attention_sinks import AutoModel
model = AutoModel.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
attention_sink_size=4, # These are the yellow blocks
attention_sink_window_size=4092, # These are the blue blocks
)
🟡 attention_sink_size: The number of initial tokens.
🔵 attention_sink_window_size: The size of the sliding window.
Compatible models
GPT-NeoX, Falcon, Mistral, Llama
Is the context window of LLMs expanded?
No. The context window remains unchanged. Only the most recent tokens and attention sinks are retained, discarding middle tokens. This means the model can only process the latest tokens. The context window remains constrained by its initial pre-training.
Can I input an extensive text, like a book, into StreamingLLM for summarization?
While you can input a lengthy text, the model will only recognize the latest tokens. Thus, if a book is an input, StreamingLLM might only summarize the concluding paragraphs, which might not be very insightful.